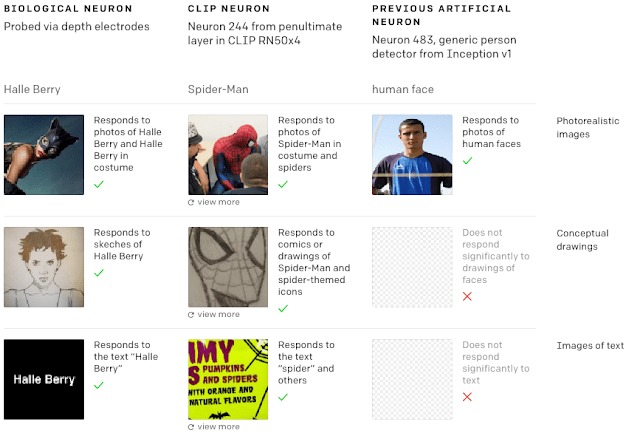
Using the tools of interpretability, we give an unprecedented look into the rich visual concepts that exist within the weights of CLIP. Within CLIP, we discover high-level concepts that span a large subset of the human visual lexicon—geographical regions, facial expressions, religious iconography, famous people and more. By probing what each neuron affects downstream, we can get a glimpse into how CLIP performs its classification.